
This blog entry is the work of Silvia Mari and Isaac Iglesias, and I am very grateful!
Introduction
Starting in the mid 70's when the first paper with chemometrics in the title appeared[1], chemometrics has evolved and matured and is now considered a functioning research area in the chemical sciences. It has expanded widely from its beginnings into many other areas including multivariate calibration, pattern recognition, and mixture resolution, and today there are several applications of interest for the NMR spectroscopists [2],[3],[4],[5].
Since Mnova 9, Mnova NMR offers a module called PCA. It is the result of our first efforts to include chemometric tools into Mnova and it is meant to give spectroscopists the possibility to interactively work with both stacked spectra and their corresponding statistical plots.
PCA module is accessed under the Advanced menu and broadly involves two subsequent steps: (1) matrix generation and (2) principal component analysis - as represented in figure 1. The overall workflow can be represented by the following illustration, where general steps available in Mnova are highlighted in blue whilst specific functionalities of this new PCA module are highlighted in yellow.
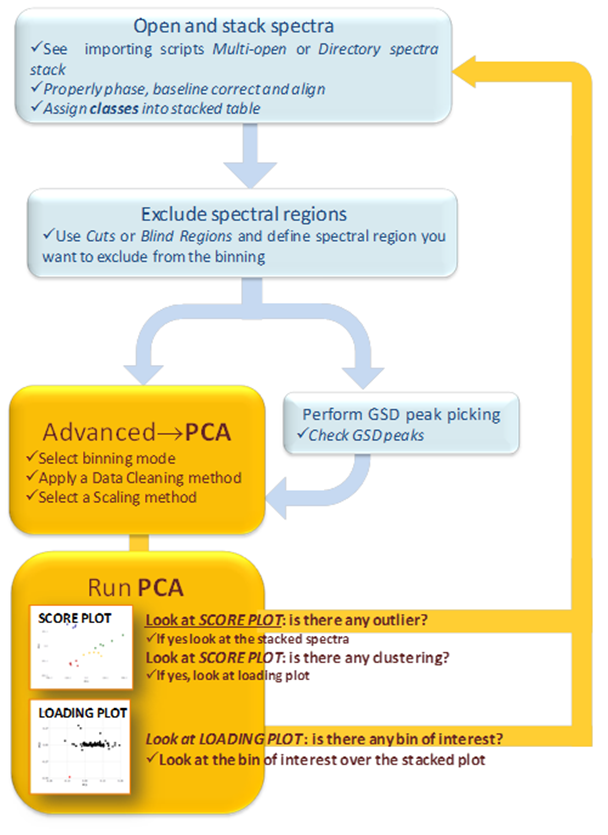
Workflow of PCA module and interaction with the NMR plugin
Workflow and features
The general workflow of the PCA module comprises several steps that User should decide and input. A detailed description of all options available under the main PCA menu are described in the corresponding Tutorial.
Here we demonstrate the use of the PCA module using a dataset of 1H NMR spectra of cell culture media. In this experiment conditioned culture media were collected at 5 different time points during cell differentiation[1]. We now ask this: can PCA classify samples according to their respective time points, and which NMR peaks are mainly responsible for this classification?
The dataset comprises 5 biological replicas for each time point, with a total of 25 samples (and 25 1D-noesypr spectra collected). After opening, processing and stacking all the spectra, the User should define obvious blind regions to be excluded from PCA analysis: solvent peaks are normally excluded. Secondly, it is always advisable to include at this stage the class to which blocks of spectra belong. In this case we classify spectra according to the day. Â These points are illustrated in figure 2 in the Stacked Table.

Class definition in Stacked Spectra table
Class definition is used in PCA only for graphical purposes. A color is assigned to spectra, tables and score plot that belong to the same class. This is used for all related data: if a spectrum is assigned a class colored yellow, then the point on the PCA plot corresponding to that spectrum will automatically inherit the color assignment.
PCA analysis could now be run from the menu: Main Menu --> Advanced, and clicking on PCA... Since this is our first analysis a blank window will appear (figure 3). By clicking on the  "+" button we can now start a new analysis. The main PCA window (figure 3, right side) comprises these choices:
- title of the analysis
- binning strategy
- Data Cleaning options
- Normalization possibilities
- Scaling functions
The order that these appear in the panel is tied to that which will be followed when the analysis is performed.
An in depth discussion of all these features is beyond the scope of this article. A detailed description can be found in the Tutorial.
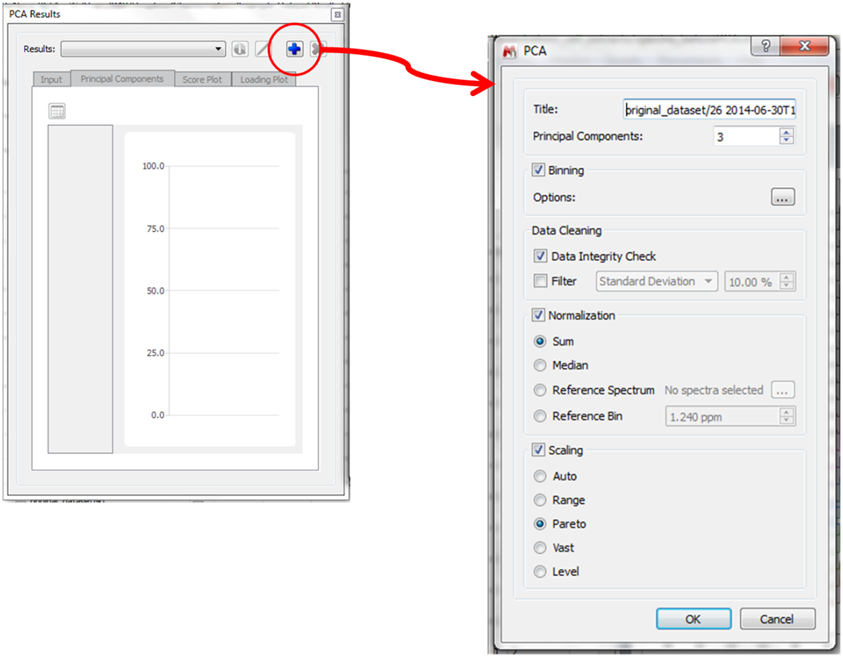
Main PCA windows
By selecting typical standard options for NMR based metabolomics (regular binning, data integrity check, normalization by the sum, and Pareto scaling) and then clicking on the "OK" button, a new panel will then appear that summarizes all PCA results. There are four main tabs:
- Input displays the input matrix as it has been used by the PCA algorithm (e.g. after the pre-processing strategy);
- Principal Components, displays a table and histogram that represents the percentages of variance explained by each calculated component;
- Score plot is the main plot that illustrates eigenvectors;
- Loading plot is the main plot that illustrates eigenvalues.
The first information is given by the Principal Component tab. As expected, component 1 (PC1) contributes very significantly to the explained variance (54%), whereas PC2 just contributes for less than half of PCA's value (see figure 4 for a histogram representation).

Histogram representation of Principal Components
Now we see the effect of class color-coding: right-click on selected rows (spectra) in the score table at the level of Class column, and then Edit Color). The PCA window has much more encoded information that is strikingly obvious (figure 5). You can see, for example, that the 5 spectra that are coded blue also cluster towards the right side of the PC1/PC2 score plot.
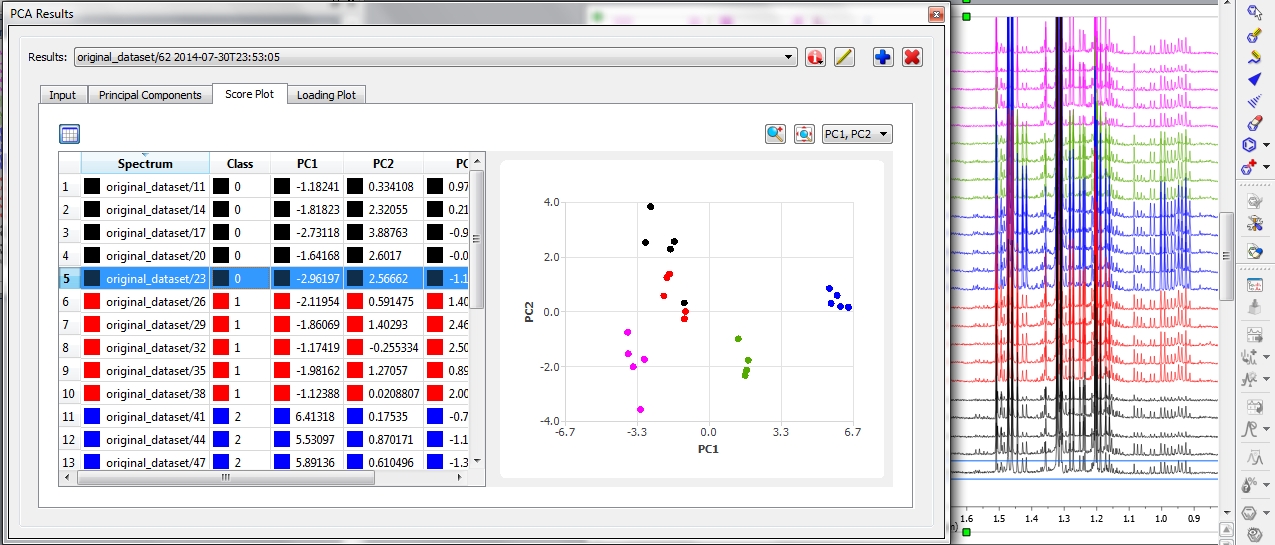
Analyzing Score plot
By quick visual inspection of the Score Plot tab, PCA was able to discriminate between classes.
For the first time point (black class) there is a spectrum (black point highlighted with the red arrow (figure 4) that possibly could be an outlier. By looking back at the stacked spectra and focusing on the corresponding spectrum, we quickly see that there are no problems with spectral phasing or alignment. It follows that this spectrum really displays some differences in peak patterns that consistently makes it lie apart from the rest of the spectra of the same class. In fact it “looks†more like the second spectral class (red).
Now we use the information contained in the loadings plot to see which parts of the spectra cause them to cluster separately from others. We start by re-coloring the loading scores by right clicking on the component of interest and selecting Auto Color option. A color gradient is then applied to each loading value (with red the highest positive value and blue the lowest negative values). Coincidentally this color-coding is visualized over the spectral bins. It is immediately clear which regions of the spectra contribute most significantly to the component of interest (see figure 6).

Analyzing the Loading plot
The analysis of the stacked plot, colour-coded by loading scores, helps in determining the most important peaks. Peak identification is then a separate task from PCA analysis, but if these significant peaks can be attributed to a compound component then we now have a full picture of the important component concentration changes through the course of the fermentation.
If necessary, a cyclic work-flow can be used to quickly refine the data and assure oneself that the results are meaningful. The user can apply changes to spectra (adjusting phase correction or peak alignment, eliminating spectra that are considered to be outliers, etc...) and re-runs PCA analysis as many time as it is necessary. The User could also explore different PCA options and easily compare the different results obtained. Figure 7 illustrates how to navigate into different PCA analysis under the same PCA windows.
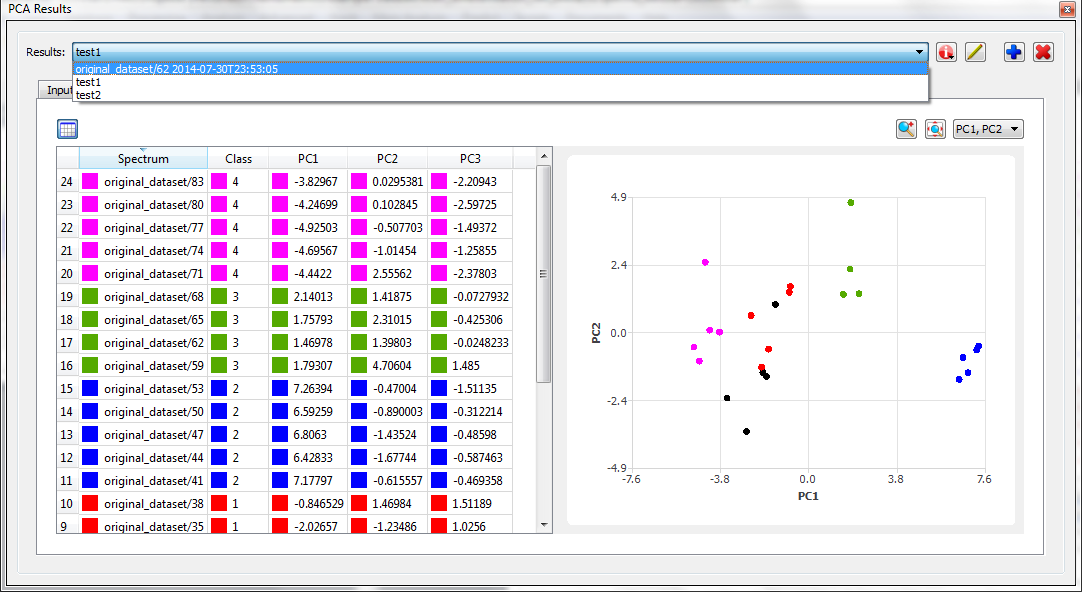
Browsing different results
Conclusions
PCA under Mnova gives Users the possibility to generate and interact with PCA plots and spectra at the same time. The User friendly interface provided by Mnova will be of great advantage also for spectroscopists who are not familiar with multivariate analysis but would like to learn more and test it.
As has always been for the Mnova community, the future of this new first step in chemometrics will be driven by User requirements. For that reason we look forward to receiving your feedback, criticisms, suggestions, comments - and lots of requests for future development. So, play with it and have fun looking at your own datasets from a completely new perspective!
Acknowledgements
We are grateful to Dr. Giovanna Musco and Dr. Jose Garcia-Manteiga for providing these data for testing purposes.
[1] Jose Manuel Garcia-Manteiga, Metabolomics of B to Plasma Cell Differentiation. J. Proteome 2011 Sep 2;10(9):4165-76.
[1] B.R. Kowalski, Chemometrics: views and propositions, J. Chem. Inf. Comp. Sci. 15 1975, 15, 4, 201–203.
[2] Chemometrics in bioreactor monitoring. Lourenço, N. D, Lopes, J. a, Almeida, C. F., Sarraguça, M. C., & Pinheiro, H. M. (2012). Bioreactor monitoring with spectroscopy and chemometrics: a review. Analytical and bioanalytical chemistry, 404, pages1211–1237 (2012)
[3] Metabonomics and chemometrics in food science and nutrition. Kuang, H., Li, Z., Peng, C., Liu, L., Xu, L., Zhu, Y., Wang, L., et al. (2012). Metabonomics approaches and the potential application in food safety evaluation. Critical reviews in food science and nutrition, 52(9), 761-774.
[4] Pharmaco-metabonomic phenotyping and chemometrics. Robertson, D. G., Reily, M. D., & Baker, J. D. (2007). Metabonomics in Pharmaceutical Discovery and Development, 526-539.
[5] Metabonomics and chemometrics in drug safety and toxicology. Griffin, J. (2004). The potential of metabonomics in drug safety and toxicology. Drug Discovery Today Technologies, 1(3), 285-293.
[6] Metabolomics of B to Plasma Cell Differentiation. Jose Manuel Garcia-Manteiga, (2011) J. Proteome Res., 10, 4165-4176.


 and Mestrelab Research, S.L. (Mestrelab)")